The Early Days
When I started my career as a dba years ago, it was the norm to use in-place patching, both for database as for grid infractructure patching.
Opatchauto didn’t exist yet and to patch a grid infrastructure installation you needed to perform a huge number of steps spanning several pages; steps as root and as grid user, unlocking and locking homes, etc.
When the home was unlocked you could use opatch to roll back patches and install the new ones and the new merge patches, during that time all your database instances using that home were down.
In short, the process to go from one bundle patch or patchset to another one, consisted in :
- unlocking homes
- removing the old patchset and extra one-off patches
- install the new patch and potential extra patches often you have collisions and you had to request merge patches.
- locking homes
Patching was no fun and very time-consuming, not to speak about rolling back if there was an issue with the freshly applied patch, all the databases using that home needed to be rollbacked as well.
I remember vividly that during one of those late-night patching efforts due to fatigue, I once didn’t pay enough attention and executed one of those steps with the wrong user, breaking my clusterware installation and causing long hours to fix my mistake.
Opatchauto executed as root improved this and made it simpler to apply patches
First out-of-place patching steps
Years later I made the transition to virtualized Exadata and after a couple of patch cycles where I continued to do things like I always did; in-place patching.
Due to the high number of VMs I started to experiment, because in-place patching didn’t scale anymore.
By accident I saw that the OEDA ( Oracle Exadata Deployment Assistant) readme contained a section about gold images, these gold images contained the fully patched version including extra Exadata-specific patches.
I downloaded the image and added them to the Guests from the Xen OVM hypervisor, I figured out how to switch from one home to the other one and wrote a very basic wrapper script.
Doing it this way gave the team the opportunity, to win a lot of time, in a more granular way.
We could patch database per database instead of the all-or-nothing approach we used previously.
Also for the grid infrastructure patching, we could really do it in a rolling fashion.
Further steps
Since then I didn’t look back and by default do out-of-place patching, in my case of course with Fleet Patching & Provision (FPP).
FPP does more than just Out-of-place patching, FPP is a patching engine, and automates all the steps you need to script manually from a centralized place, it will always do so using the MAA recommendations and takes advantage of new HA features when available.
Summary
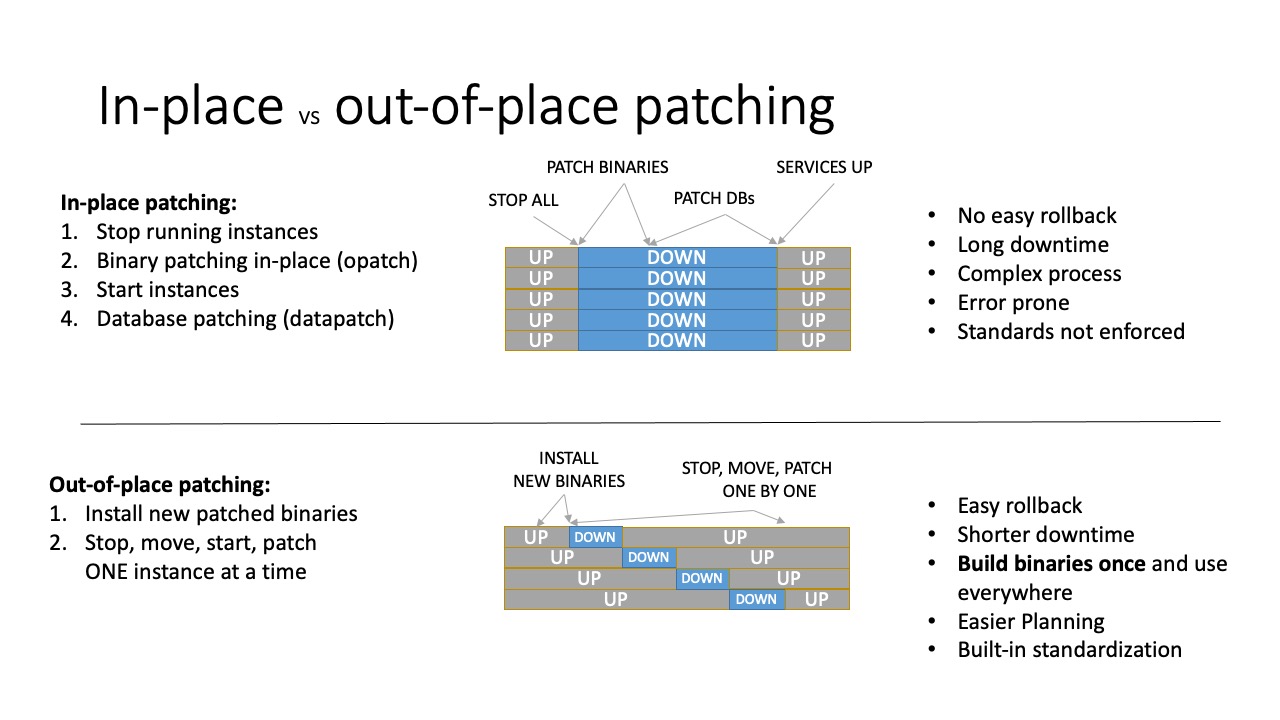
In summary, why should you patch out-of-place?
- You can prepare in advance : build once reuse
- Out-of-place patching is faster : shorter downtime
- Easy rolling patching
- Easy rollback
- You can patch database by database instead of the all-or-nothing approach
In short out-of-place patching is the only way forward.
Make sure also to check out Fleet Patching & Provisioning it will help you tremendously with deploying an out-of-place patching strategy, by automating most of the steps.
Further reading :
Further Reading
Oracle Fleet Patching & Provisioning landing page
https://www.oracle.com/goto/fpp
Oracle Fleet Patching & Provisioning 19c documentation
https://docs.oracle.com/en/database/oracle/oraclegrantvirtualbox
FPP workshop on LiveLabs
https://apexapps.oracle.com/pls/apex/dbpm/r/livelabs/view-workshop?wid=599
FPP by Example Blog Series
https://blogs.oracle.com/maa/post/fleet-patching-provisioning-by-example-intro



